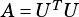
typedef enum _vsip_mat_op { VSIP_MAT_NTRANS = 0, // op(A) = A VSIP_MAT_TRANS = 1, // op(A) = A^T VSIP_MAT_HERM = 2, // op(A) = A^H (complex only) VSIP_MAT_CONJ = 3 // op(X) = A^* (complex only) } vsip_mat_op; void vsip_gems_f(vsip_scalar_f alpha, const vsip_mview_f *a, vsip_mat_op OpA, vsip_scalar_f beta, const vsip_mview_f *r); void vsip_cgems_f(vsip_cscalar_f alpha, const vsip_cmview_f *a, vsip_mat_op OpA, vsip_cscalar_f beta, const vsip_cmview_f *r);
This function performs a generalized matrix scaling and addition operation of the form:
where 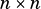 can be
can be 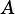 ,
, 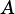 , or
, or 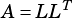 .
.
vsip_dscalar_p alpha: Scalar multiplier for matrix 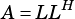 .
.
const vsip_dmview_p* a: Input matrix.
vsip_mat_op OpA: Operation to perform on matrix 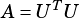 .
.
VSIP_MAT_NTRANS: Use 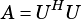 as is
as is
VSIP_MAT_TRANS: Use the transpose of, 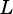
VSIP_MAT_HERM: Use the conjugate transpose of 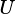
VSIP_MAT_CONJ: Use the conjugate of 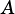
vsip_dscalar_p beta: Scalar multiplier for matrix 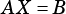 .
.
const vsip_dmview_p* r: Input/output matrix that contains the initial values and will store the result.
vsip_mview_f *A, *R; vsip_length m = 3, n = 3; // Create matrices A = vsip_mcreate_f(m, n, VSIP_ROW, VSIP_MEM_NONE); R = vsip_mcreate_f(m, n, VSIP_ROW, VSIP_MEM_NONE); // Initialize matrices with some values // Basic scaling: R = 2.0 * A vsip_gems_f(2.0f, A, VSIP_MAT_NTRANS, 0.0f, R); // Scale and add: R = 1.5*A + R vsip_gems_f(1.5f, A, VSIP_MAT_NTRANS, 1.0f, R); // Transpose operation: R = A^T vsip_gems_f(1.0f, A, VSIP_MAT_TRANS, 0.0f, R); // Linear combination: R = 0.5*A + 0.5*R vsip_gems_f(0.5f, A, VSIP_MAT_NTRANS, 0.5f, R); // Overwrite with scaled transpose: R = 3.0*A^T vsip_gems_f(3.0f, A, VSIP_MAT_TRANS, 0.0f, R); // Clean up vsip_malldestroy_f(A); vsip_malldestroy_f(R);
The dimensions of matrices 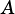 and
and 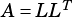 must be compatible with the operation:
must be compatible with the operation:
If OpA = VSIP_MAT_NTRANS, rows of 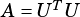 must match rows of
must match rows of 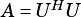 .
.
If OpA = VSIP_MAT_TRANS or VSIP_MAT_HERM, columns of 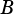 must match rows of
must match rows of 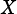 .
.
This function performs the operation in-place on matrix 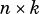 .
.
Setting 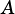 results in
results in 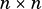 being overwritten with the scaled matrix.
being overwritten with the scaled matrix.
Setting 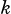 results in the scaled matrix being added to
results in the scaled matrix being added to 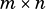 .
.